The compressor gets the credit
Machine learning is the science of credit assignment.
Jürgen Schmidhuber, Annotated History of Modern AI and Deep Neural Networks
In 1997, Schmidhuber published LSTM. It appeared in Neural Computation, a journal the field actually read, and the experiments ran on tasks and hardware that other labs could replicate. It got credited to him without controversy. Six years earlier, in 1991, the same Schmidhuber had published the core mechanism behind what we now call the Transformer: outer-product key-value attention, trained end to end by gradient descent. He called it “Fast Weight Programmer,” buried it in a tech report, and demonstrated it on toy problems nobody could replicate. That one got credited to Google in 2017.
If you think the explanation is politics or institutional power, you have to explain why the politics worked in Schmidhuber’s favor for LSTM and against him for FWP, in the same community, within six years. I do not think politics explains it. I think the difference is that LSTM was easy to absorb and FWP was not, and I wrote a paper trying to formalize what that means when you take it seriously.
The concept I ended up calling “absorption cost” is just how much work it takes the next reader to integrate your idea into what they already know. LSTM had low absorption cost because it was published in a widely-read journal, the paper was framed around a concrete technical problem (vanishing gradients in RNNs), and any lab could replicate the experiments. FWP had high absorption cost because “fast weights” was a niche concept in 1991, the format was a tech report with limited distribution, and the experiments were too small to prove the mechanism worked on anything real. When Google republished the mechanism in 2017 as the “Transformer,” everything that had made FWP expensive to absorb was gone: the name was clean, the results were dramatic, the compute was cheap, and Google’s distribution meant every ML practitioner saw it within weeks.
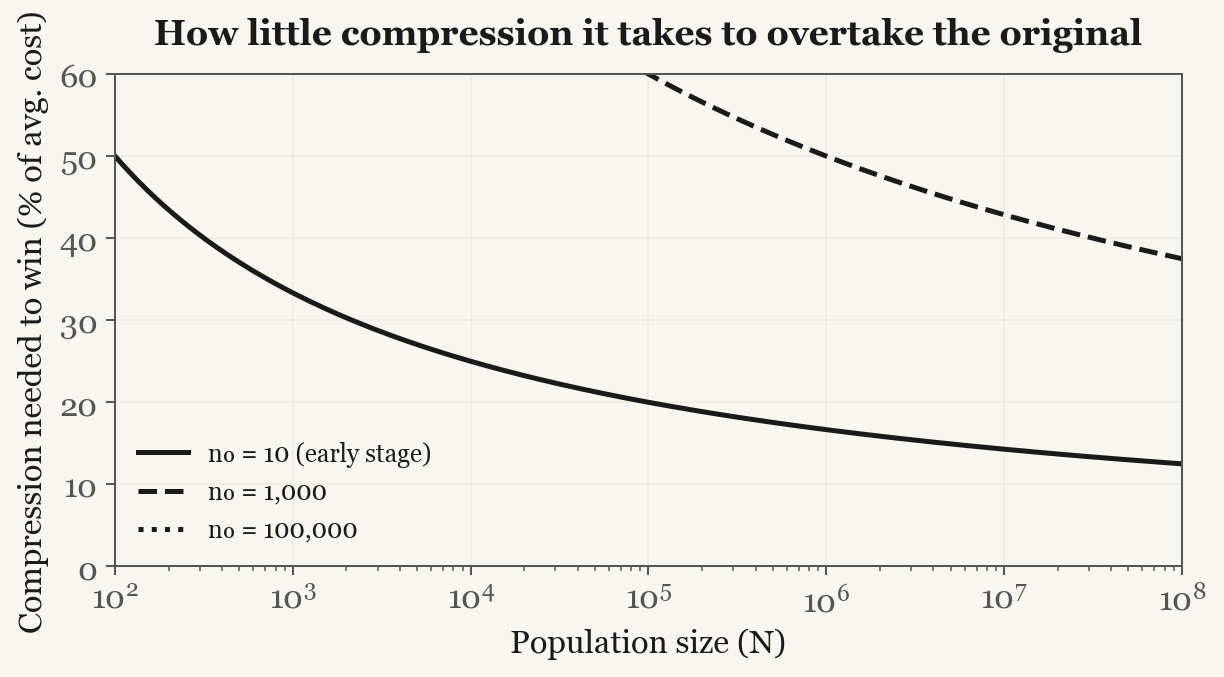
The question I wanted to answer in the paper is how much of an absorption-cost advantage a reformulation actually needs to overtake the original. It turns out to be very little.
This pattern is not unique to Schmidhuber. Lorentz and Poincaré had the math of special relativity before Einstein, who dropped the ether scaffolding and rederived it from two postulates that did not require a background in electrodynamics. Amari published the Hopfield network a decade before Hopfield. Linnainmaa published backpropagation years before it was applied to neural networks. In every case the credited version is the one that cost less to absorb.
What I find more interesting than the historical pattern is what the formalization says about civilizations that have not existed yet. If you have a population of N agents that are individually rational and have no social biases at all, the equilibrium credit weight on compression still goes to 1 as N grows. The reason is arithmetic: novelty value is realized once when a new idea enters the knowledge base, but a reduction in absorption cost is realized across every agent who reads the idea. At any meaningful population size, the N-times multiplier on compression drowns out the one-time novelty contribution.
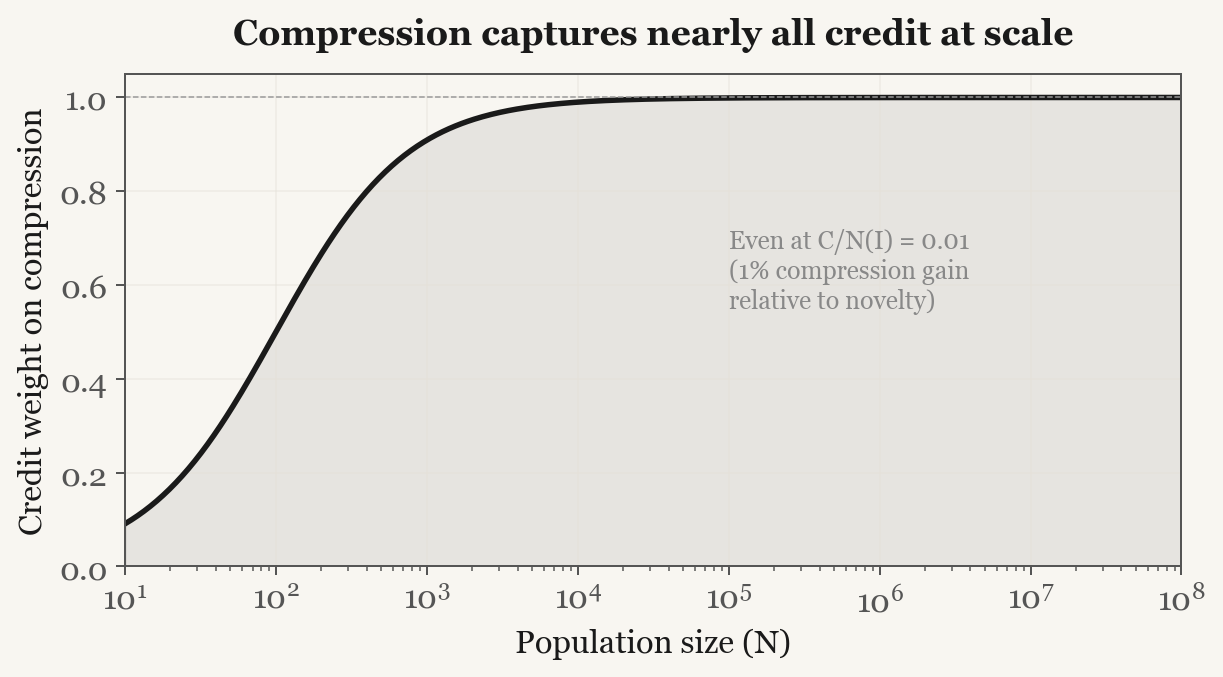
A machine civilization of a million rational agents with perfect information would credit compressors more aggressively than humans do. What people call “credit misattribution” is a bandwidth property of any information-processing population, and no amount of rationality or fairness removes it.
The model also says something about how a civilization should allocate its effort. Under reasonable assumptions about diminishing returns on parallel search, the optimal fraction of agents doing frontier invention scales as 1/N. For a million agents, that is less than one in ten thousand. Everyone else should be compressing, communicating, reformulating, teaching, and distributing.
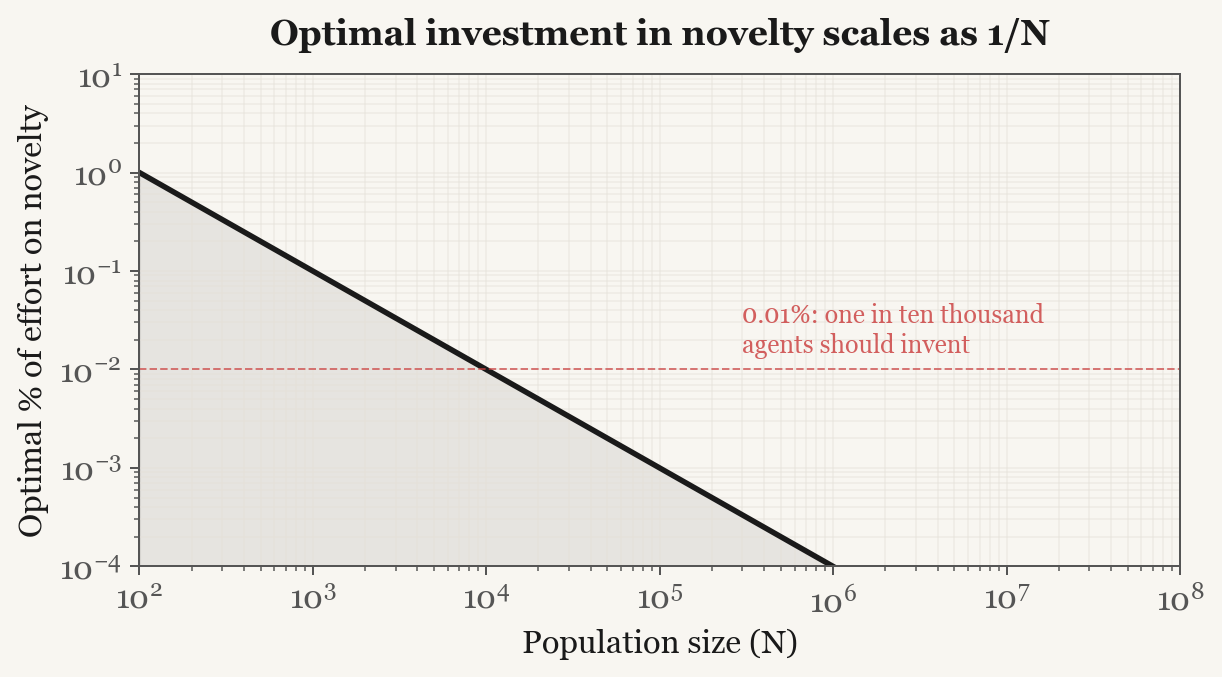
Most work in any mature scientific field is already synthesis, replication, extension, and teaching. The small fraction doing genuinely novel work looks like stagnation if you expect everyone to be pushing the frontier, but the model says that allocation is close to optimal.
There is one more result I keep thinking about. Schmidhuber proposed compression progress as the intrinsic motivation signal for curious AI agents: a system should maximize how efficiently it compresses new observations. If you apply that criterion one level up, to a research community deciding what metadata to keep about its own knowledge base, attribution is the first thing it drops. Knowing who published first does not help compress the next observation. Under that objective, priority records are pure overhead. And correcting for the resulting credit allocation is intractable in general, because it requires evaluating counterfactuals about what would have been discovered if a specific person had never existed, which means simulating the civilization’s entire search process on a different branch. Every unit of effort spent on that correction is effort not spent inventing or compressing, so a civilization that attempts it grows strictly slower than one that does not.
I think Schmidhuber is the Einstein of our time without Einstein’s social skills, and I think he is right about almost every priority dispute he has raised. I also think the hours he spends on those disputes are, by the accounting of his own framework, the worst use of his time. LSTM got credited to him because he compressed it well. FWP did not get credited to him because he did not. The system he is fighting produced both outcomes, and the paper’s math explains why.
Full paper: The Compressor Gets the Credit.